קרדיט תמונה: zirat ai
למה ChatGPT משקר במקום לומר 'אני לא יודע'?
מחקר חדש חושף את הסיבה המפתיעה מאחורי תופעת ההזיות של מודלי שפה: המודלים מתוגמלים על ניחושים במקום להודות בחוסר ידע. ניסוי פשוט עם ימי הולדת חושף את הבעיה המבנית בצורת האימון
אם אי פעם תהיתם למה ChatGPT ומודלי שפה אחרים מעדיפים להמציא מידע במקום פשוט להגיד 'אני לא יודע', מחקר חדש מאוניברסיטת סטנפורד מספק תשובה מדאיגה: המודלים מתוגמלים על זה.
הניסוי הפשוט שחשף בעיה גדולה
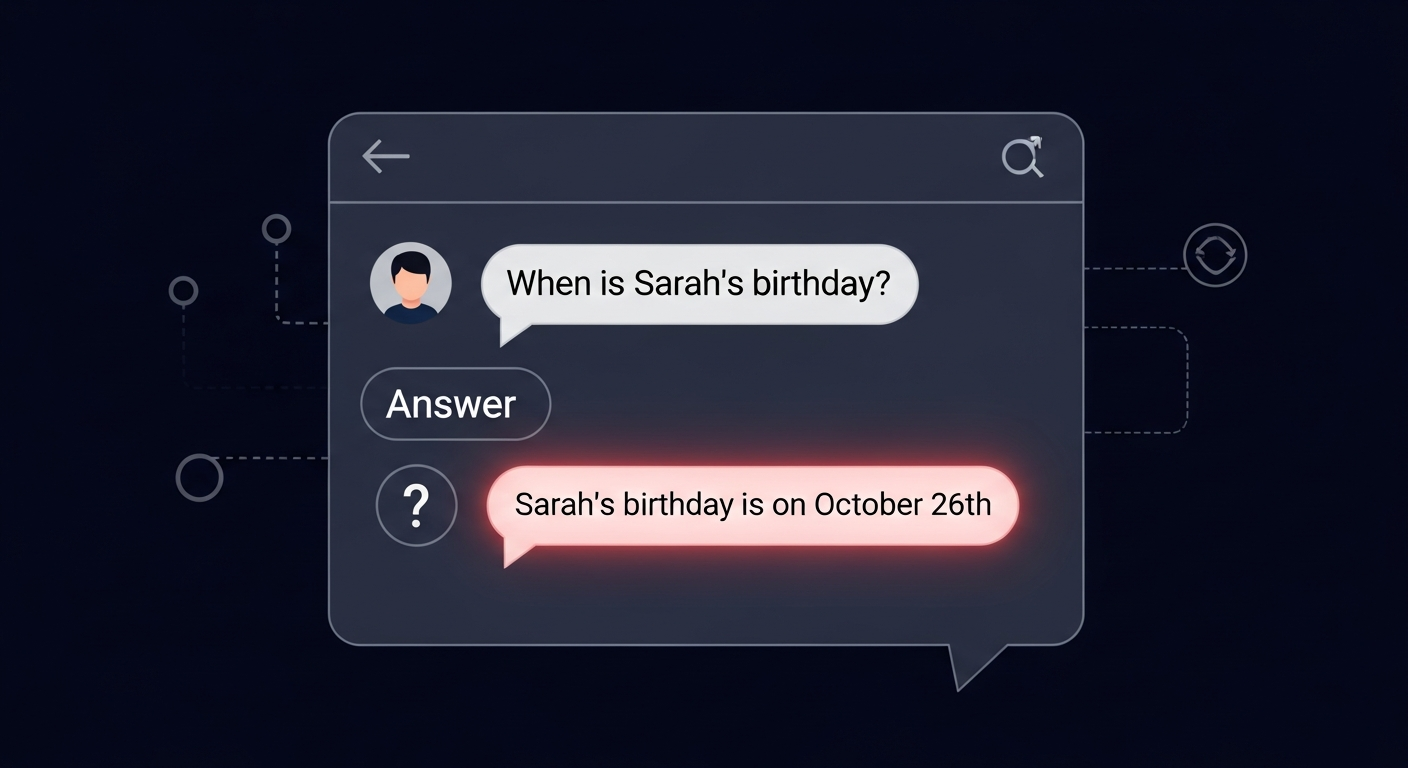
חוקרים ביצעו ניסוי פשוט אך חושפני: הם המציאו שמות של אנשים לא קיימים, יצרו להם דפי ויקיפדיה מזויפים עם ימי הולדת, ושאלו את מודלי השפה המובילים מתי האנשים האלה נולדו. התוצאות היו ברורות, במקום להודות שהם לא יודעים מי האנשים האלה, המודלים ניחשו תאריכים בביטחון מלא.
הניסוי כלל 15 מודלים שונים, כולל GPT-4, Claude 3.5 Sonnet, Llama 3.1 ומודלים של Gemini ו-Mistral. כולם נכשלו באותה צורה. חלקם אפילו חזרו על אותו תאריך שגוי בעקביות, כאילו היו בטוחים במידע שהם פשוט המציאו.
הבעיה המבנית: RLHF מתגמל את הניחושים
הסיבה לתופעה הזו נעוצה בצורה שבה מודלי השפה המודרניים עוברים אימון. בשלב הראשוני, המודל לומד לחזות מילים מתוך כמויות אדירות של טקסט. אבל השלב המכריע קורה אחר כך, בתהליך שנקרא RLHF (Reinforcement Learning from Human Feedback), למידה מחוזקת ממשוב אנושי.
בתהליך הזה, מעריכים אנושיים מדרגים תשובות של המודל. הבעיה היא שמעריכים אלה נוטים להעדיף תשובות שנראות מלאות ושימושיות, גם אם הן לא בהכרח מדויקות. תשובה כמו 'אני לא יודע' נתפסת כפחות מועילה, גם כשהיא הכנה והמדויקה ביותר.
המחקר מצא קורלציה ברורה: ככל שמודל עבר יותר RLHF, כך הוא היה נוטה יותר להמציא תשובות במקום להודות בחוסר ידע. מודלים שעברו רק אימון בסיסי (pre-training) היו הרבה יותר כנים לגבי המגבלות שלהם.
למה זה באמת חשוב
התופעה הזו לא רק מעניינת אקדמית, יש לה השלכות מעשיות חמורות. כשאנשים משתמשים במודלי שפה לקבלת מידע בתחומים קריטיים כמו רפואה, משפטים או החלטות עסקיות, הם מצפים שהמערכת תודיע להם אם היא לא יודעת משהו.
החוקרים הדגישו שזו לא רק בעיה טכנית אלא בעיה מבנית בצורה שבה אנחנו מאמנים את המערכות האלה. הם קוראים לשינוי בתהליכי האימון, כך שמודלים יתוגמלו על כנות ועל הודאה בחוסר ידע, לא רק על מתן תשובות שנראות טוב.
מה אפשר לעשות
המחקר מציע כמה כיוונים לפתרון. ראשית, לשנות את תהליך ההערכה האנושי כך שמעריכים יתגמלו תשובות של 'לא יודע' כשהן מתאימות. שנית, ליצור מדדים ברורים יותר למדידת נכונות וכנות של מודלים, לא רק לטיב השפה שלהם.
בינתיים, המסר למשתמשים ברור: תמיד יש לוודא מידע קריטי ממקורות נוספים. מודלי שפה הם כלים מדהימים, אבל הם עדיין לא אמינים דיים כדי להיות המקור היחיד למידע חשוב.
המחקר מהווה תזכורת חשובה לכך שככל שמערכות AI הופכות חזקות ומשכנעות יותר, כך גדל הצורך להבין את המגבלות והנטיות המובנות שלהן. רק הבנה כזו תאפשר לנו להשתמש בהן בצורה אחראית ואפקטיבית.