קרדיט תמונה: zirat ai
חוקרי MIT פיתחו מודל שיכול לעבד טקסטים פי 100 מאורך החלון הקונטקסטואלי
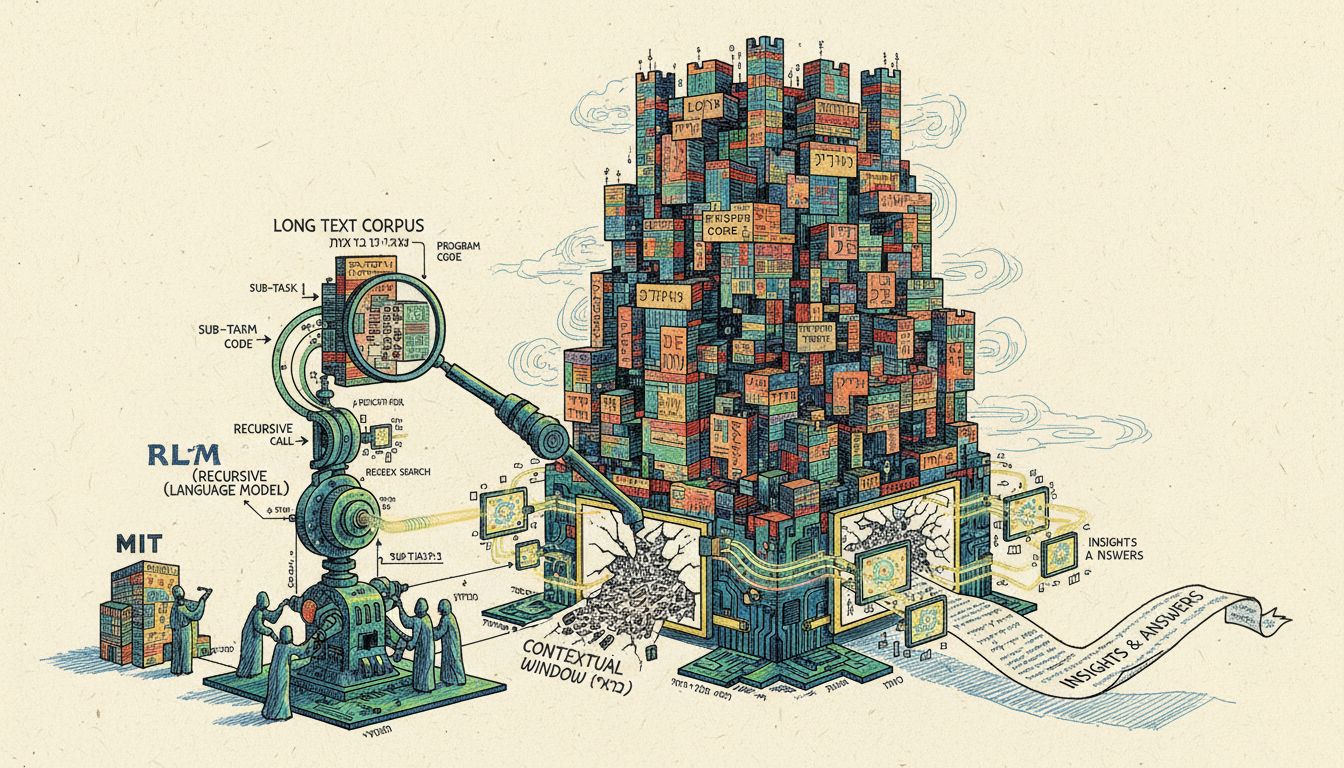
מחקר חדש מ-MIT מציג את RLM, פרדיגמה חדשנית המאפשרת למודלי שפה גדולים לעבד טקסטים באורך של עשרות מיליוני טוקנים, פי 100 מעבר לחלון ההקשר הרגיל, תוך שימוש ברקורסיה וקוד לפירוק המשימות
חוקרים ב-MIT במחקר חדש שפורסם גילו שאפשר להרחיב באופן דרמטי את יכולת העיבוד של מודלי שפה גדולים באמצעות גישה חדשנית שמטפלת בטקסטים ארוכים כסביבה חיצונית במקום להזין אותם ישירות למודל.
המחקר, שנערך על ידי אלכס ז'אנג, טים קראסקה ועומר ח'טאב, מציג את RLM (Recursive Language Models), פרדיגמת הסקה חדשה שמאפשרת למודלי שפה לעבד טקסטים באורך של עשרות מיליוני טוקנים, עד פי 100 מעבר לחלון ההקשר הסטנדרטי.
הבעיה: חלון ההקשר המוגבל
מודלי שפה מתקדמים כמו GPT-5 מוגבלים לחלון הקשר של כ-272 אלף טוקנים. אבל גם בתוך המגבלה הזו, הם סובלים מתופעה שנקראת "ריקבון הקשר" (context rot), שבה איכות התשובות יורדת ככל שהטקסט הנכנס מתארך. זה הופך לבעיה משמעותית במיוחד כשמדובר במשימות שדורשות עיבוד של מאות מיליוני טוקנים, כמו ניתוח מאגרי קוד ענקיים או מחקר מעמיק.
הגישות הקיימות לטיפול בבעיה, כמו דחיסת הקשר או סיכום חוזר, לא מספיק יעילות במשימות שדורשות גישה צפופה לכל חלקי הטקסט. הן מניחות שאפשר לשכוח פרטים מוקדמים כדי לפנות מקום לתוכן חדש.
הפתרון: טיפול בטקסט כסביבה חיצונית
התובנה המרכזית של RLM היא שטקסטים ארוכים לא צריכים להיכנס ישירות לרשת הנוירונים. במקום זה, הם מטופלים כחלק מהסביבה שהמודל מתקשר איתה באופן סימבולי ורקורסיבי.
במקום להזין את כל הטקסט למודל, RLM יוצר סביבת תכנות (REPL) שבה הטקסט נשמר כמשתנה. המודל מקבל רק מטא-דאטה על הטקסט, כמו אורכו וקטע קצר ממנו, ואז כותב קוד שבוחן, מפרק וקורא לעצמו באופן רקורסיבי על חלקים שונים של הטקסט.
הגישה הזו מאפשרת למודל להפעיל עצמו על קטעי טקסט ספציפיים בצורה פרוגרמטית, בלי להיות מוגבל לחלון ההקשר הפיזי שלו.
תוצאות מרשימות במבחנים
החוקרים בחנו את RLM על ארבע משימות שונות ברמות מורכבות שונות, החל מחיפוש מידע פשוט ועד לניתוח מורכב של זוגות נתונים. במבחנים השתמשו במודלים מתקדמים כמו GPT-5 ו-Qwen3-Coder-480B.
הממצאים היו דרמטיים. בעוד ש-GPT-5 רגיל הראה ירידה חדה בביצועים ככל שהטקסט התארך, RLM שמבוסס על אותו מודל שמר על ביצועים גבוהים גם בטקסטים שחרגו בהרבה מחלון ההקשר המקורי. במשימות מורכבות במיוחד, כמו OOLONG-Pairs שדורשת עיבוד של כל זוגות הנתונים בטקסט, ההפרש היה מהותי.
במשימת BrowseComp-Plus, למשל, שכוללת מענה על שאלות מתוך אלף מסמכים, RLM עם GPT-5 השיג דיוק של 91.3 אחוזים, לעומת 0 אחוזים של המודל הבסיסי שלא הצליח בכלל להכיל את כל הנתונים.
אימון מודל קטן שמתחרה בענקים
בניסוי מעניין במיוחד, החוקרים אימנו מודל קטן יחסית של 8 מיליארד פרמטרים (Qwen3-8B) להיות RLM מקורי. באמצעות אימון פשוט על 1,000 דוגמאות בלבד מתחומים לא קשורים, הם השיגו שיפור ממוצע של 28.3 אחוזים בארבע משימות.
המודל המאומן הזה, RLM-Qwen3-8B, הצליח להגיע לרמת ביצועים קרובה ל-GPT-5 בשלוש משימות, למרות שהוא קטן בהרבה. זה מראה שהגישה לא דורשת מודלים ענקיים והיא ניתנת לשיפור מהיר עם אימון ממוקד.
איך זה עובד בפועל
כשהמודל מקבל טקסט ארוך, הוא כותב קוד שמחלק אותו לקטעים, מבצע חיפוש מבוסס ביטויים רגולריים למציאת מידע רלוונטי, וקורא לעצמו על כל קטע. התוצאות נשמרות במשתנים, והמודל יכול לשלב אותן בצורה תכנותית.
למשל, במשימה שדרשה מציאת מידע על פסטיבל בפיליפינים, RLM חיפש אוטומטית קטעים שמכילים את המילה "festival" ושמות של מקומות בפיליפינים, ואז עיבד רק את הקטעים הרלוונטיים.
משמעות למערכות AI עתידיות
המחקר פותח דלת לעידן חדש של מערכות AI שיכולות לטפל במשימות מורכבות שדורשות עיבוד של כמויות אדירות של מידע. זה יכול לשנות את הדרך שבה אנו משתמשים ב-AI למחקר מדעי, ניתוח מסמכים משפטיים, הבנת מאגרי קוד גדולים ועוד.
בניגוד לגישות קודמות, RLM משלב את היתרונות של כתיבת קוד, גישה למידע חיצוני ורקורסיה בצורה שמאפשרת לבצע עבודה סמנטית שגודלה יכול להיות פרופורציונלי לריבוע אורך הטקסט, ולא רק ליניארי.
הקוד של המחקר זמין כקוד פתוח ב-GitHub, מה שמאפשר לחוקרים ומפתחים נוספים לבנות על העבודה הזו ולשפר אותה.