סף חיזוי נטישת לקוחות הוא החלטת תמחור: כך מודלי AI שורפים מיליונים
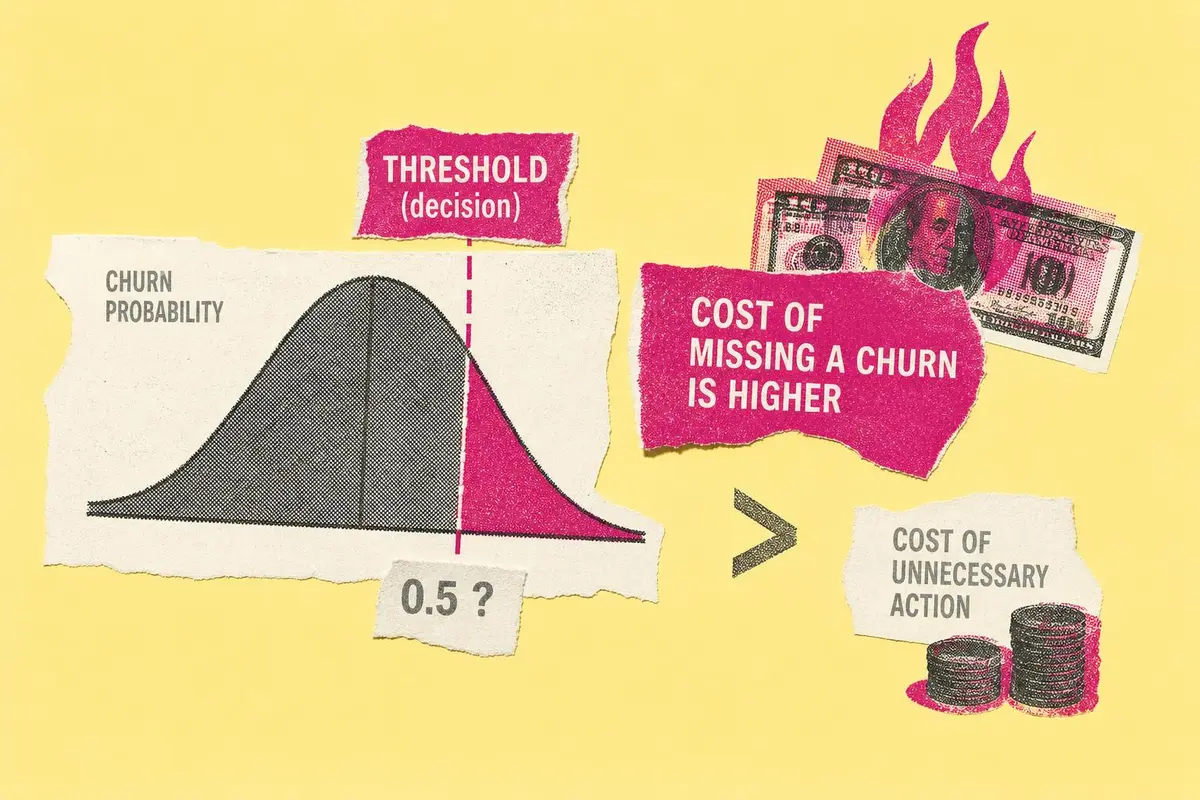
מודלי חיזוי נטישה נמדדים לעיתים בדיוק, F1 ו-AUC, אך ההחלטה העסקית האמיתית מסתתרת במקום אחר: הסף שבו הופכים הסתברות לפעולה. כאשר עלות פספוס לקוח נוטש גבוהה פי כמה מעלות טיפול מיותר, סף ברירת המחדל 0.5 עלול להיות טעות יקרה מאוד.
לא כל תחזית טובה היא החלטה טובה
בעולם מדעי הנתונים קל להתאהב במדדים נקיים כמו דיוק, F1 או AUC. הם נוחים להשוואה, נראים טוב בדוחות, ולעיתים יוצרים תחושה שמודל חיזוי נטישת לקוחות בשל לפרודקשן. אבל במערכות עסקיות, השאלה החשובה אינה רק האם המודל צדק, אלא כמה כסף עלתה כל טעות. ניתוח שפורסם ב-Towards Data Science סביב מאגר IBM Telco Customer Churn מדגים היטב את הפער הזה: סף סיווג של 0.5 אינו בחירה טכנית ניטרלית, אלא החלטת תמחור סמויה.
רוצה להישאר מעודכן ב-AI?
הירשם לדיוור השבועי שלנו וקבל עדכונים, המלצות על כלים, חדשות ודוחות מיוחדים
כאשר המודל אומר שללקוח יש הסתברות נטישה של 40 אחוז, והמערכת מתעלמת ממנו משום שהסף מוגדר ל-0.5, הארגון בעצם אומר שעלות איבוד הלקוח נמוכה מספיק כדי לא להצדיק התערבות. אבל אם גיוס לקוח חדש עולה מאות דולרים, ואם הלקוח היה עשוי להמשיך לשלם עוד חודשים רבים, ההתעלמות הזו יכולה להיות יקרה פי כמה משליחת הצעה, שיחת שירות או טיפול נקודתי.
הבעיה: מדדים סטטיסטיים במקום כלכלת יחידה
בפרויקטי נטישה רבים, במיוחד בדוגמאות פופולריות על מאגרי נתונים לימודיים, מתייחסים לסף ההחלטה כאל פרט שולי. מאמנים XGBoost, מאזנים מחלקות עם SMOTE, משווים מטריקות, ומציגים מטריצת בלבול. מה שחסר הוא Profit Curve, כלומר עקומה שמחשבת את העלות הכספית הכוללת בכל סף אפשרי.
המשמעות העסקית דרמטית. טעות מסוג False Negative, לקוח שהמודל סימן כמי שיישאר אך בפועל נטש, כוללת לא רק אובדן הכנסה עתידית אלא גם עלות רכישת לקוח חלופי. לעומת זאת, False Positive, לקוח שסומן בטעות כמועד לנטישה, עלול לעלות בעיקר את מחיר ההתערבות השיווקית או השירותית. אם היחס בין הטעויות הוא למשל 13 ל-1, כפי שמראה הדוגמה במאמר, סף 0.5 פשוט אינו מתאים למציאות העסקית.
למה LTV חייב להימדד דרך הישרדות לקוח
אחת הטעויות הנפוצות היא לחשב ערך חיי לקוח, LTV, באמצעות ממוצעים גסים: הכנסה חודשית ממוצעת כפול משך חיים ממוצע. זה נוח, אך לעיתים מטעה. לקוחות יקרים יותר אינם בהכרח נאמנים יותר, לקוחות במסלול חודשי מתנהגים אחרת מלקוחות בחוזה ארוך, והכנסה חודשית אינה משתנה בלתי תלוי בסיכון הנטישה.
כאן נכנסת לתמונה אנליזת הישרדות, ובפרט Kaplan-Meier. במקום להניח קצב נטישה קבוע, היא מעריכה את ההסתברות של לקוח להישאר פעיל לאורך זמן ומתרגמת אותה לתרומה מצטברת לאחר עלות רכישה. עבור הנהלות שיווק, מוצר ופיננסים, זו אינה אלגנטיות סטטיסטית בלבד. זו הדרך להבין מתי לקוח מחזיר את עלות הגיוס, אילו סגמנטים מצדיקים השקעה גבוהה יותר, ואיפה התערבות שימור באמת מייצרת ערך.
הסף הנכון אינו תמיד הסף התיאורטי
בספרות על סיווג רגיש לעלות קיים סף בייסיאני אופטימלי: עלות False Positive חלקי סכום עלויות שתי הטעויות. אך הנוסחה הזו מניחה שההסתברויות של המודל מכוילות. במציאות, מודלים שאומנו על נתונים מאוזנים מלאכותית באמצעות SMOTE נוטים להפיק הסתברויות שאינן משקפות את שיעור הנטישה האמיתי. לכן סף תיאורטי של 0.07 עשוי להפסיד לסף אמפירי של 0.03 לאחר סריקה פשוטה של כל הספים.
המסקנה למנהלי דאטה ברורה: לפני שמפעילים קמפיין שימור על בסיס מודל AI, צריך לכייל הסתברויות או לבצע סריקת ספים לפי עלות עסקית אמיתית. עדיף עוד יותר לבנות ספים שונים לפי סגמנט, כי עלות התערבות ללקוח חדש, לקוח ותיק, לקוח רווחי או לקוח מתוסכל ממוצר מסוים אינה זהה.
השורה התחתונה
חיזוי נטישה אינו תחרות Kaggle. זו מערכת החלטה פיננסית. מודל עם F1 גבוה וסף שגוי עלול להפסיד יותר כסף ממודל מעט פחות מדויק אך מכוון היטב לכלכלת היחידה. בעידן שבו ארגונים מטמיעים AI בתהליכי שיווק, שירות ומוצר, היתרון לא יגיע ממודל שמנבא טוב יותר בלבד, אלא ממודל שמחליט נכון יותר.