סוכן AI לחיפוש עבודה: איך מודל קטן מסנן משרות בלינקדאין ומסביר התאמה לקורות חיים
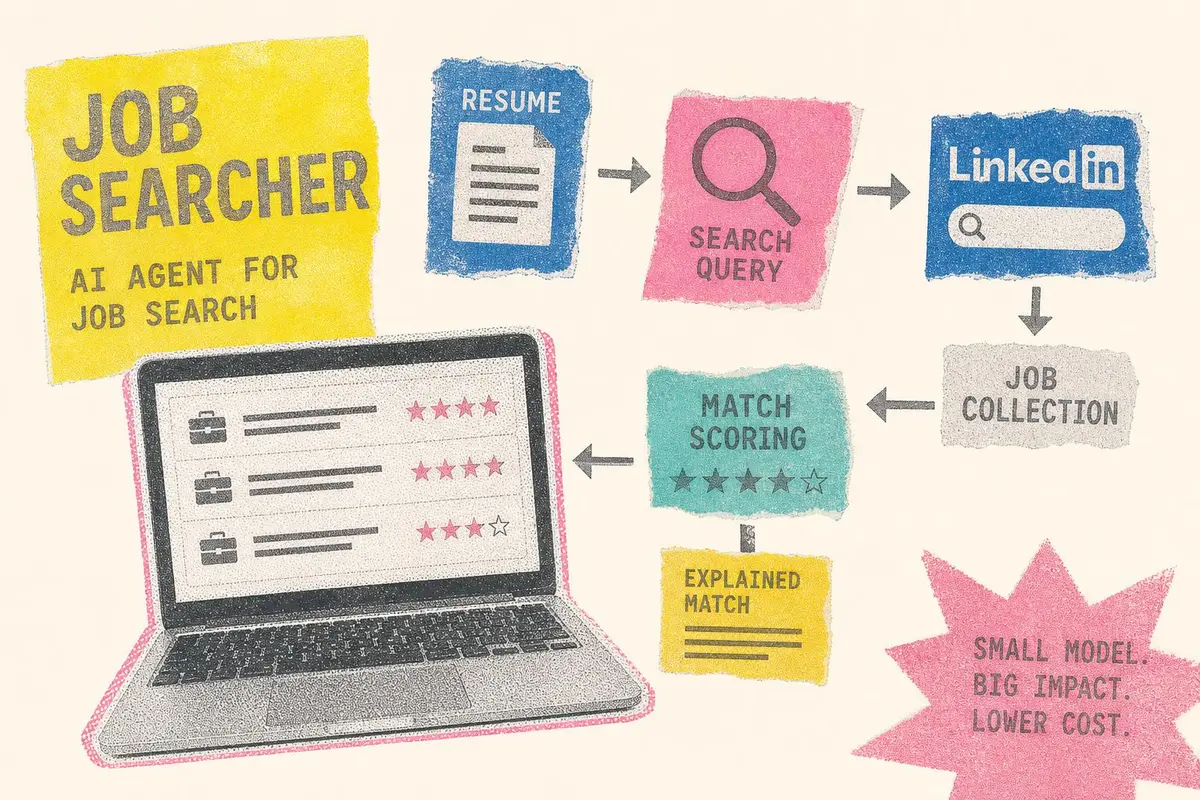
פרויקט Job Searcher מציג כיוון מעשי לסוכני AI ייעודיים: העלאת קורות חיים, יצירת שאילתות חיפוש, איסוף משרות ודירוג התאמה מנומק. מעבר להדגמה, הוא מדגים כיצד זיקוק ידע ממודל גדול למודל קטן עשוי להפוך תהליכים עסקיים חוזרים לאוטומציה שקופה וזולה יותר.
חיפוש עבודה כבעיה של סוכן AI
חיפוש עבודה לבוגרים חדשים ולעובדים בתחילת הדרך הפך בשנים האחרונות למטלה כמעט תעשייתית: מאות מודעות, ניסוחים חוזרים, סינון ידני ואינספור הגשות למשרות שאינן בהכרח מתאימות. פרויקט Job Searcher, שפורסם בקהילת Hugging Face במסגרת Build Small Hackathon, מציע גישה אחרת: לא עוד מנוע שמחזיר רשימה ארוכה של משרות, אלא סוכן AI שמנסה להבין את קורות החיים, לבנות שאילתות חיפוש, לאסוף משרות ולדרג אותן לפי התאמה מוסברת.
רוצה להישאר מעודכן ב-AI?
הירשם לדיוור השבועי שלנו וקבל עדכונים, המלצות על כלים, חדשות ודוחות מיוחדים
החשיבות של הפרויקט אינה רק בממשק הנוח. הוא מייצג מגמה רחבה יותר בתעשייה: מעבר מצ'אטבוטים כלליים לסוכנים אנכיים, קטנים יחסית, שמאומנים לבצע תהליך עסקי מוגדר מקצה לקצה. במקרה הזה, התהליך הוא התאמה בין מועמד למשרה, אך אותו דפוס רלוונטי גם לרכש, תמיכה, ניהול לידים ומיון מסמכים.
מזיקוק ידע למודל תפעולי קטן
הארכיטקטורה מעניינת משום שהיא מפרידה בין מודל מורה למודל תלמיד. המורה, DeepSeek V4 Pro, שימש ליצירת נתוני אימון ותיוגים מנומקים, אך אינו נדרש בזמן השימוש. התלמיד, Qwen3-8B, קטן בהרבה ומותאם באמצעות LoRA כדי לבצע שתי משימות מרכזיות: יצירת שאילתות חיפוש בסגנון לינקדאין והערכת התאמת משרות לקורות חיים.
מאגר הנתונים נבנה סביב כ-2,500 קורות חיים, שעל בסיסם הפיק המודל שאילתות חיפוש. לאחר מכן נאספו כ-10,000 מודעות משרה באמצעות JobSpy, וכל זוג של קורות חיים ומשרה קיבל ציון בחמישה ממדים: התאמת כישורים, רלוונטיות ניסיון, השכלה והסמכות, התאמה ענפית והתאמת דרגת בכירות. זהו פרט מהותי, כי המערכת אינה מסתפקת בציון מספרי עמום. היא מייצרת נימוק, ובכך הופכת את הדירוג לבר בדיקה ולשיפור.
למה שני מתאמי LoRA עדיפים כאן על מודל אחד
אחד הלקחים הטכניים החשובים הוא שהפרדת המשימות לשני מתאמי LoRA ניצחה ניסיון לאחד הכול למתאם אחד. כאשר אותו מודל נדרש גם להפיק שאילתות מובנות וגם לכתוב הערכות טקסטואליות, נוצרה זליגה בין פורמטים: JSON הופיע במקום פרוזה, ופרוזה הופיעה במקום פלט מובנה. ההפרדה בין ראשי התמחות שונים על אותו מודל בסיס היא תזכורת לכך שבמערכות AI ייצוריות, הנדסת מוצר חשובה לא פחות מגודל המודל.
גם בחירת הפריסה מעשית: שימוש ב-llama.cpp, קוונטיזציה ל-Q4_K_M והרצה ב-ZeroGPU מאפשרים להדגים מודל ייעודי בלי עלויות ענן כבדות. עבור סטארטאפים וצוותי מוצר, זהו מסר ברור: לא כל בעיית AI מחייבת מודל ענק או תשתית יקרה, אם הדאטה, הפורמט ותהליך ההסקה מתוכננים היטב.
ההזדמנות העסקית והסיכון האתי
שוק הגיוס בשל לשכבת אוטומציה חדשה. מועמדים רוצים סינון טוב יותר, מגייסים רוצים התאמות מדויקות יותר, ופלטפורמות תעסוקה רוצות להגדיל המרות. סוכן שמסביר מדוע משרה אחת עדיפה על אחרת עשוי לחסוך זמן ולשפר החלטות. עם זאת, יש כאן גם שאלות לא פתורות: פרטיות קורות חיים, הטיות בדירוג התאמה, תלות במקורות חיצוניים כמו לינקדאין, ושאלה רגולטורית סביב איסוף מידע ממודעות משרה.
הכיוון הנכון אינו להחליף שיקול דעת אנושי, אלא להפחית רעש. אם סוכן כזה מציג רשימה קצרה, מנומקת ושקופה, הוא יכול להפוך מכלי נוחות לכלי תשתית. Job Searcher הוא עדיין פרויקט ניסיוני, אך הוא מצביע היטב על העתיד הקרוב: מודלים קטנים יותר, ממוקדי משימה, שיושבים בתוך תהליכי עבודה אמיתיים ומחזירים לא רק תשובה, אלא הסבר שניתן להתווכח איתו.