קרדיט תמונה: Amazon Web Services
חילוץ טקסט מ-PDF ב-S3 בזמן אמת: איך לשפר את חיפוש המסמכים בארגון
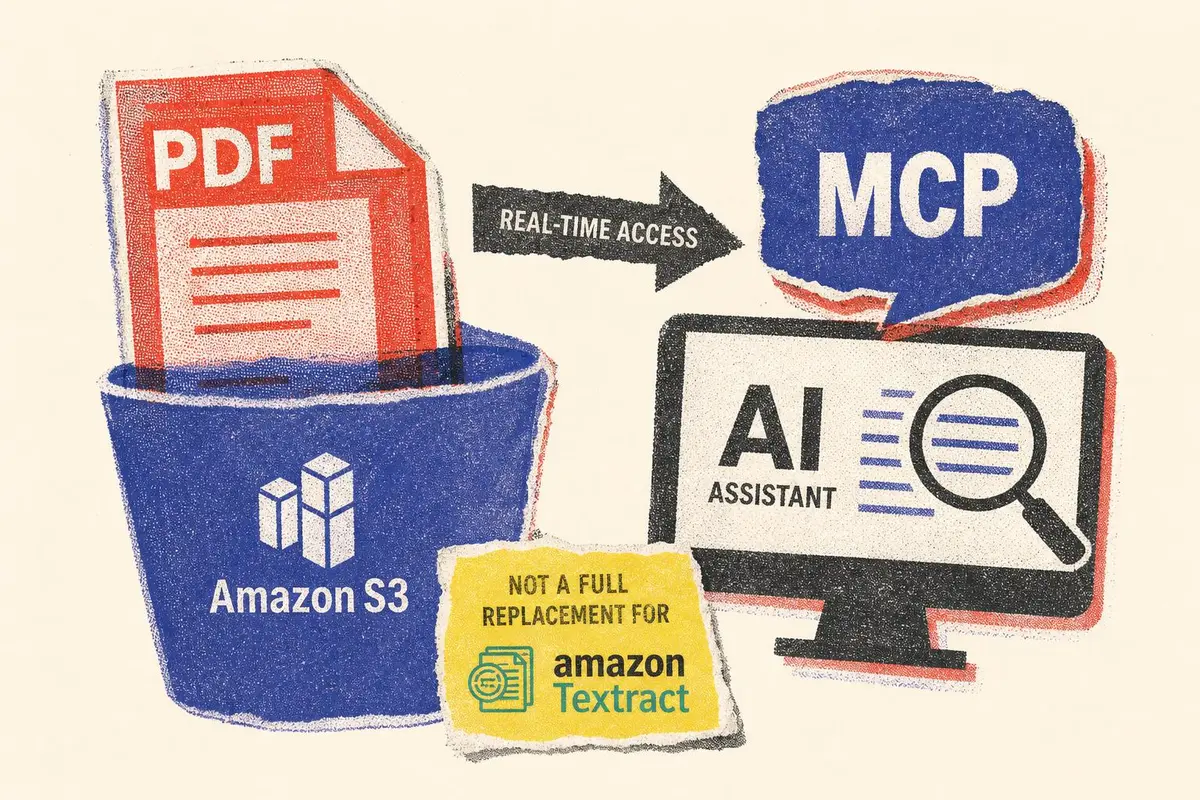
פתרון MCP חדש מאפשר לעוזרי AI לקרוא קובצי PDF טקסטואליים ישירות מ-Amazon S3 בזמן אמת, בלי תהליכי Batch כבדים. עבור צוותי משפט, ציות ופיננסים, זו עשויה להיות שכבת גישה מהירה וזולה למסמכים, אך לא תחליף מלא ל-Amazon Textract.
חילוץ PDF בזמן אמת: הבעיה הארגונית שמסתתרת בתוך S3
בארגונים רבים, Amazon S3 הפך למחסן המסמכים בפועל: חוזים, דוחות כספיים, מדיניות ציות, מסמכי הנהלה ותיעוד רגולטורי. הבעיה מתחילה ברגע שבו משתמש עסקי צריך תשובה עכשיו, לא בעוד שעה ולא אחרי סיום תהליך Batch. עורך דין בשיחה עם לקוח, קצין ציות מול מבקר או סמנכ״ל כספים לפני ישיבה אינם מחפשים מערכת עיבוד מסמכים מלאה. הם צריכים גישה מיידית לפסקה הנכונה.
רוצה להישאר מעודכן ב-AI?
הירשם לדיוור השבועי שלנו וקבל עדכונים, המלצות על כלים, חדשות ודוחות מיוחדים
בפוסט שפורסם ב-AWS Blogs מציגים פאני פארצ׳ה וסייבאל גוש דפוס ארכיטקטוני מעניין: שרת MCP שמתחבר ל-Amazon S3, מוריד קובץ PDF טקסטואלי, מחלץ ממנו טקסט באמצעות ספריית Python ומחזיר את התוכן לעוזר AI או לממשק שורת פקודה. לכאורה זה פתרון קטן, כמעט תשתיתי. בפועל, הוא מסמן כיוון רחב יותר בשוק ה-AI הארגוני: מעבר ממודלים שממתינים להזנת מידע, אל סוכנים שמתחברים בזמן אמת למקורות הידע של הארגון.
מה MCP מוסיף לעולם ה-AI הארגוני
Model Context Protocol, או MCP, הוא ניסיון לייצר שכבת תקשורת סטנדרטית בין יישומי AI לבין מקורות נתונים חיצוניים. במקום שכל ארגון יבנה אינטגרציה ייעודית בין צ׳אטבוט, אחסון קבצים, בסיס נתונים ומערכות פנימיות, MCP מגדיר דרך אחידה לחשוף כלים ופעולות למודלים. במקרה הנוכחי, הכלי הוא חילוץ טקסט מ-PDF שנמצא ב-S3.
הערך העסקי אינו רק בחיסכון בעלויות, אף שהפער יכול להיות משמעותי בסביבות ניסוי ופיתוח. הערך האמיתי הוא קיצור הזמן בין שאלה עסקית לבין תשובה מבוססת מסמך. כאשר עוזר AI מסוגל לשלוף את הטקסט המקורי מתוך מסמך, ולא להסתמך על זיכרון, אינדקס ישן או העתק ידני, רמת האמון בתשובה עולה. זה רלוונטי במיוחד בענפים מפוקחים, שבהם ניסוח מדויק של סעיף חוזי או מדיניות פנימית חשוב יותר מסיכום יצירתי.
לא תחליף ל-Textract, אלא שכבה משלימה
חשוב להבין את גבולות הפתרון. שרת MCP כזה מתאים בעיקר לקובצי PDF שבהם הטקסט כבר מקודד במסמך. הוא אינו מבצע OCR, אינו מפענח סריקות, אינו מבין טבלאות מורכבות ואינו מחלץ שדות מטפסים. במקרים כאלה Amazon Textract נשאר הכלי המתאים, במיוחד כאשר נדרשים עיבוד בקנה מידה גדול, הבנת מבנה עמוד, טפסים, טבלאות ורמת שירות ארגונית.
לכן ההחלטה אינה בין MCP לבין Textract, אלא בין שני סוגי עומסי עבודה. אם מדובר בשאלה אינטראקטיבית על מסמך טקסטואלי, שרת MCP מינימלי יכול להספיק ואף להיות יעיל יותר. אם מדובר בצבר מסמכים סרוקים, בתהליך ציות פורמלי או בהפקת נתונים מובנית, שירות מנוהל כמו Textract מצדיק את העלות ואת המורכבות.
המשמעות הרחבה: AI שמתחבר למסמכים במקום להעתיק אותם
הפתרון הזה גם מצביע על שינוי בתכנון מערכות RAG וסוכני AI. במקום להזרים כל מסמך מראש לווקטור דאטהבייס, אפשר במקרים מסוימים לאפשר גישה ישירה למסמך המקור בעת הצורך. גישה כזו מפחיתה שכפול מידע, מצמצמת בעיות עדכניות ומפשטת אבטחה, משום שהגישה נשענת על הרשאות IAM קיימות ועל תיעוד גישה ב-CloudTrail.
עם זאת, פריסה ארגונית רצינית תדרוש שכבות נוספות: בקרת הרשאות עדינה לפי מסמך, ניטור שימוש, הגבלת גודל קבצים, סינון מידע רגיש ואולי מטמון למסמכים שנקראים שוב ושוב. השלב הבא הטבעי הוא ארכיטקטורה היברידית, שבה מסמכים פשוטים נשלפים דרך MCP, מסמכים מורכבים נשלחים ל-Textract, ותוצאות חשובות נכנסות לחיפוש סמנטי.
בסופו של דבר, החידוש כאן אינו בקוד Python שמחלץ טקסט מ-PDF. החידוש הוא בתפיסה: עוזרי AI ארגוניים צריכים גישה מבוקרת, בזמן אמת, למידע החי של הארגון. MCP עשוי להפוך לאחת השכבות המרכזיות שמאפשרות זאת.