Amazon Bedrock משנה את עיבוד המסמכים החכם
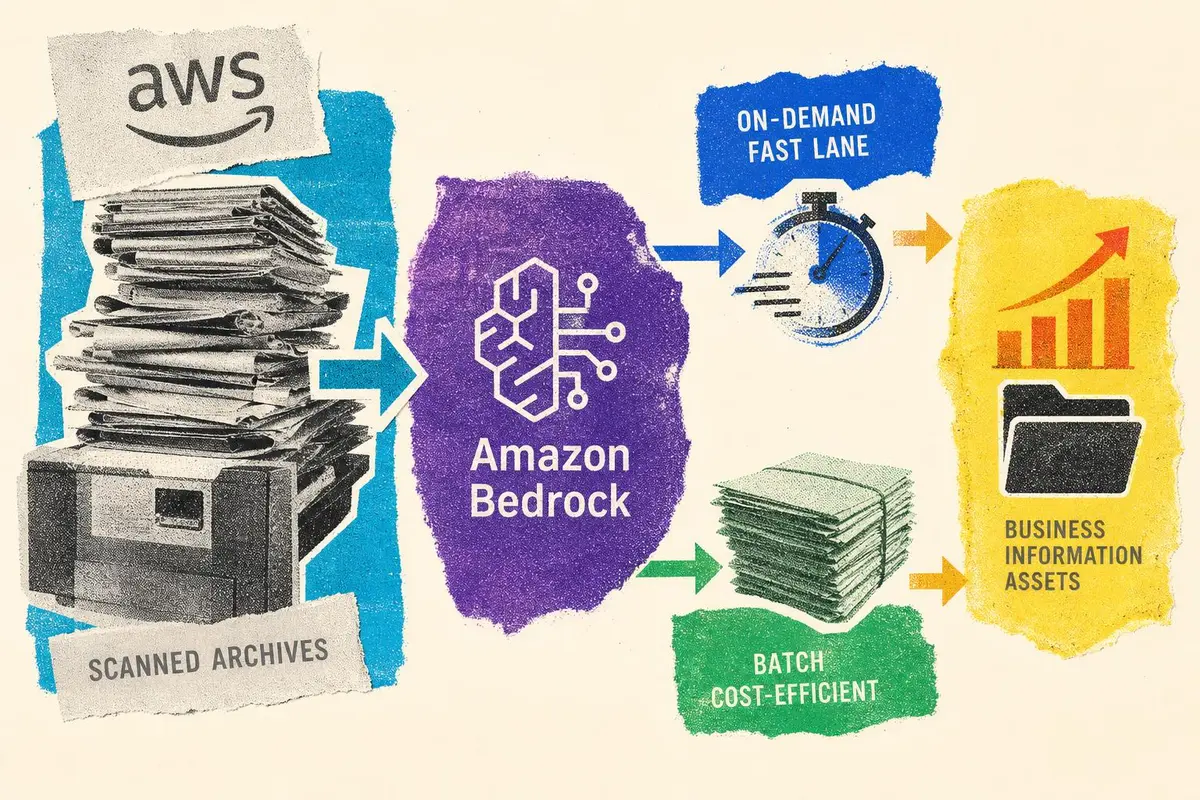
AWS מציגה ארכיטקטורה מעשית לעיבוד מסמכים חכם באמצעות Amazon Bedrock, המשלבת מסלול מהיר לפי דרישה עם מסלול אצווה חסכוני. מעבר להדגמה הטכנית, מדובר בתבנית עבודה חשובה לארגונים שמנסים להפוך ארכיונים סרוקים לנכסי מידע עסקיים פעילים.
עיבוד מסמכים חכם נכנס לשלב התעשייתי
אחד האתגרים הגדולים ביותר בארגונים ותיקים אינו מחסור בנתונים, אלא העובדה שחלק עצום מהם כלוא במסמכים סרוקים, חוזים, טפסים, תיקים משפטיים ומסמכי נדל"ן שאינם ניתנים לחיפוש או ניתוח פשוט. הפתרון שפרסמה AWS סביב Amazon Bedrock מצביע על שינוי חשוב בשוק: מעבר מניסויי GenAI נקודתיים לארכיטקטורות ייצור שמסוגלות לטפל במיליוני מסמכים, תוך איזון בין מהירות, עלות ודיוק.
רוצה להישאר מעודכן ב-AI?
הירשם לדיוור השבועי שלנו וקבל עדכונים, המלצות על כלים, חדשות ודוחות מיוחדים
הגישה מבוססת על שני מסלולים משלימים. המסלול הראשון מיועד לעיבוד לפי דרישה, כאשר מסמך בודד נשלח לתור SQS ומפעיל פונקציית Lambda שמורידה את הקובץ מ-S3, ממירה PDF סרוק לתמונות, שולפת הנחיות מ-Amazon Bedrock Prompt Management, מפעילה מודל שפה רב-מודאלי ושומרת את הפלט ב-DynamoDB. זהו מסלול מתאים למצבים שבהם המשתמש מצפה לתשובה בתוך שניות, למשל בדיקת מסמך בזמן טיפול בלקוח או במהלך תהליך חיתום.
למה שילוב בין On-demand ל-Batch חשוב עסקית
המסלול השני מיועד לאצווה, והוא משמעותי במיוחד לארגונים בעלי ארכיונים היסטוריים גדולים. במקום להפעיל מודל על כל מסמך בנפרד, המערכת אוספת בקשות בתור SQS רגיל, מתזמנת עיבוד באמצעות EventBridge, יוצרת קובצי JSONL עבור Amazon Bedrock Batch Inference ומבצעת את ההסקה באופן אסינכרוני. לפי AWS, בבדיקות שבוצעו עלות Bedrock במסלול האצווה הייתה נמוכה בכ-50% בהשוואה למסלול לפי דרישה. זהו פער שיכול להפוך פרויקט AI מארכיטקטורה יקרה מדי לפרויקט בעל היתכנות פיננסית.
הנקודה המעניינת אינה רק חיסכון בענן. בארגונים גדולים, מסמכים אינם אחידים. חוזה חכירה אחד עשוי לכלול טבלה, אחר רשימה ממוספרת, ושלישי תרשים או שרטוט. לכן היכולת לבחור ברמת המסמך את מזהה המודל ואת גרסת הפרומפט היא קריטית. זו אינה רק נוחות הנדסית, אלא שכבת ממשל AI שמאפשרת לשפר דיוק, לבדוק גרסאות הנחיה, וליישם מדיניות שונה לפי סוג מסמך, מחלקה עסקית או דרישת רגולציה.
הארכיטקטורה חושפת גם את מגבלות ה-GenAI
הפתרון מדגים בצורה טובה את המציאות הנוכחית של מודלים רב-מודאליים. למשל, כאשר מודל דוגמת Claude Sonnet 4 מוגבל למספר תמונות בכל קריאה, מסמך ארוך חייב להתפצל למקטעים. לכן המערכת מנהלת מזהי מסמך, מספר מקטעים ומזהה מקטע, ושומרת את התוצאות לצד מדדי ביצוע. זו תזכורת לכך ש-GenAI ארגוני אינו מסתכם בקריאה למודל, אלא דורש תזמור, ניהול שגיאות, מניעת כפילויות, ניטור ועלויות צפויות.
בהיבט התפעולי, השימוש ב-Lambda מתאים לעומסים בינוניים ולזרימות עבודה אלסטיות, אך AWS עצמה מרמזת על כיוון המשך: העברת הקוד ל-AWS Batch לעיבוד של עשרות אלפי מסמכים בכל עבודת אצווה. עבור בנקים, חברות ביטוח, משרדי עורכי דין, חברות אנרגיה וגופי ממשל, זהו בדיוק ההבדל בין אוטומציה מחלקתית לבין מפעל נתונים מבוסס AI.
השורה התחתונה
הערך האמיתי של הארכיטקטורה הוא בהפיכת מסמכים לא מובנים לנתונים מובנים שניתן לחפש, לאמת, לנתח ולשלב במערכות עסקיות. Amazon Bedrock מספק כאן לא רק גישה למודלי שפה, אלא מסגרת פעולה סביב פרומפטים, הסקה באצווה, תורים, אחסון ותיעוד תוצאות. עבור מנהלי טכנולוגיה, המסר ברור: פרויקטי עיבוד מסמכים עם AI צריכים להיבנות מראש עם שני מצבי פעולה, מהיר וחסכוני, אחרת הם ייתקעו בין אב טיפוס מרשים לבין מערכת ייצור שאינה משתלמת.