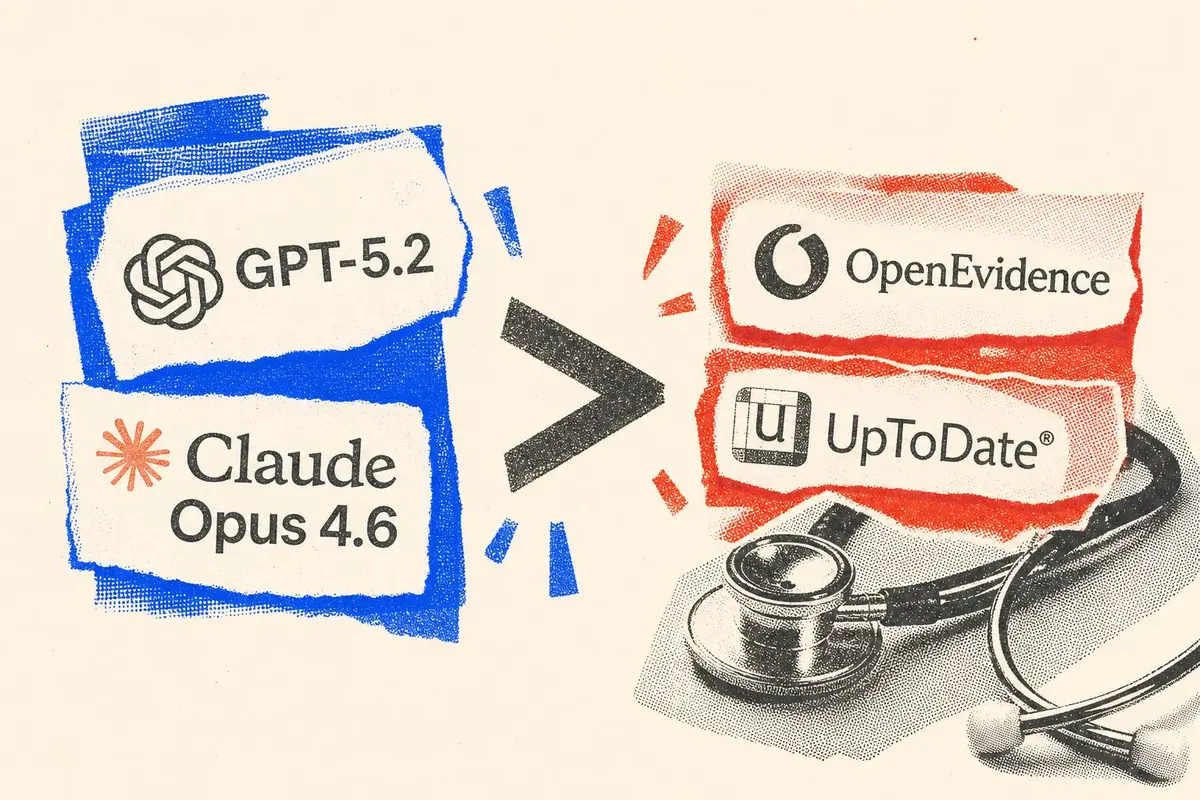
מודלי AI רפואיים מפסידים למודלים גנריים: מה זה אומר?
מחקר חדש שפורסם ב-Nature Medicine מגלה כי מודלי AI גנריים כמו GPT-5.2 ו-Claude Opus 4.6 עוקפים מודלים רפואיים ייעודיים כמו OpenEvidence ו-UpToDate בבחינות רישוי, בהתאמה לשיפוט קליני ובשאילתות של רופאים בפועל. הממצאים מטילים ספק בהנחת היסוד של כל ענף ה-AI הרפואי הייעודי.
כשהכלל מנצח את המומחה
שנים ארוכות נשענה תעשיית ה-AI הרפואי על הנחה פשוטה: אם תיקח מודל שפה חזק ותוסיף לו ידע רפואי מעמיק ומאומת, תקבל כלי שרופאים יכולים לסמוך עליו יותר מאשר על כל צ'אטבוט גנרי. על בסיס הנחה זו גייסה חברת OpenEvidence מאות מיליוני דולרים, ו-UpToDate בנתה שכבת AI משלה. הגיון השוק נשמע מוצק.
רוצה להישאר מעודכן ב-AI?
הירשם לדיוור השבועי שלנו וקבל עדכונים, המלצות על כלים, חדשות ודוחות מיוחדים
מחקר שפורסם לאחרונה ב-Nature Medicine מאתגר את ההנחה הזו בצורה ישירה. חוקרים מ-NYU Langone השוו בין OpenEvidence ו-UpToDate Expert AI לבין שלושה מודלים גנריים - GPT-5.2, Gemini 3.1 Pro ו-Claude Opus 4.6 - על פני שלוש קטגוריות: בחינות רישוי רפואי, מדדי התאמה לשיפוט קליני ו-100 שאילתות של רופאים מהשטח. התוצאות נבחנו בעיוורון על ידי רופאים פעילים. המודלים הגנריים ניצחו בכל שלוש הקטגוריות (כפי שפורסם על ידי Psychology Today).
אבל הממצא החריף יותר היה שהכלים הרפואיים הייעודיים לא הצליחו להניב ביצועים טובים יותר מ-Google Search AI Overview, כלי שרוב המשתמשים כלל אינם מודעים לקיומו.
האריתמטיקה שמישהו היה צריך לעשות
אחת הדרכים להבין את הממצאים היא דרך הסתכלות על היחסים הכמותיים. מודלי frontier מאומנים על טריליוני מילים. ספרות ביו-רפואית שלמה מייצגת מאות מיליארדי מילים. כשמוסיפים שכבת ידע רפואי למודל שכבר ספג טריליונים של מילים בתחומי ביולוגיה, כימיה, סטטיסטיקה ופרמקולוגיה, התוספת המצטברת עשויה לייצג עשירית האחוז מסך הידע הקיים. השאלה אינה אם ידע מתמחה מוסיף ערך, אלא אם התוספת מספיקה כדי להצדיק פרמיה מסחרית.
להשוואה, ב-2023 השקיעה Bloomberg משאבים כבדים ב-BloombergGPT, מודל פיננסי ייעודי שאומן על מיליארדי tokens של נתוני שוק קנייניים. הטיעון היה זהה כמעט: פיננסים הם תחום מורכב ובעל השלכות שמודלים גנריים לא יוכלו לשלוט בו. בסופו של דבר, BloombergGPT ביצע ביצועים דומים למודלים גנריים במשימות פיננסיות.
לאן עובר הערך
השאלה הנכונה אינה אם מומחיות קלינית חשובה - היא חשובה. השאלה היא היכן טמון הערך כשהבינה הכללית הופכת לכשירה לטפל ברוב מה שמודלים ייעודיים אמורים היו לשלוט בו.
אם מודלים גנריים ימשיכו להתאמן לרמות ביצוע קליניות, הבידול התחרותי יעבור לאזורים אחרים: נתונים קלינייים קנייניים, אינטגרציה לתהליכי עבודה קיימים, אמון מוסדי, ציות רגולטורי ויכולת הפעלה בתוך סביבות בריאות מורכבות. המודל עצמו הופך לתשתית, והערך עולה בסטאק.
עבור חברות ה-digital health הישראליות - מ-Medial EarlySign ועד לסטארטאפים בתחום ה-clinical decision support - המשמעות ישירה: יתרון תחרותי לא ייבנה עוד על גבי fine-tuning של מודל רפואי ייעודי, אלא על גבי נתונים קנייניים, אינטגרציה עמוקה עם מערכות קיימות כמו HIS ו-EMR, ועל הצד הרגולטורי שנשאר מחסום כניסה אמיתי.
מחסום שלא היה לנצח
המחקר עצמו ממתן את מסקנותיו: משימות ייעודיות מאוד עדיין עשויות להרוויח מגישות ממוקדות-תחום, ועובדה קלינית בודדת יכולה להיות מכרעת במקרה הנכון. מקרי הקצה האלה אמיתיים, אך הם מייצגים חלק הולך ומצטמצם מהתמונה הכוללת.
ה-AI הרפואי בנה את זהותו סביב האמונה שמורכבות קלינית דורשת התמחות קלינית. מה שהעדויות מראות כעת הוא שהשכבה הייעודית פחות קריטית ממה שהניחו, בגלל שהבסיס מתחתיה הפך לכשיר באופן יוצא דופן. המחסום היה אמיתי. הוא פשוט לא היה קבוע.