ארכיטקטורת RAG חכמה: LLM כבורר באחזור מידע ארגוני
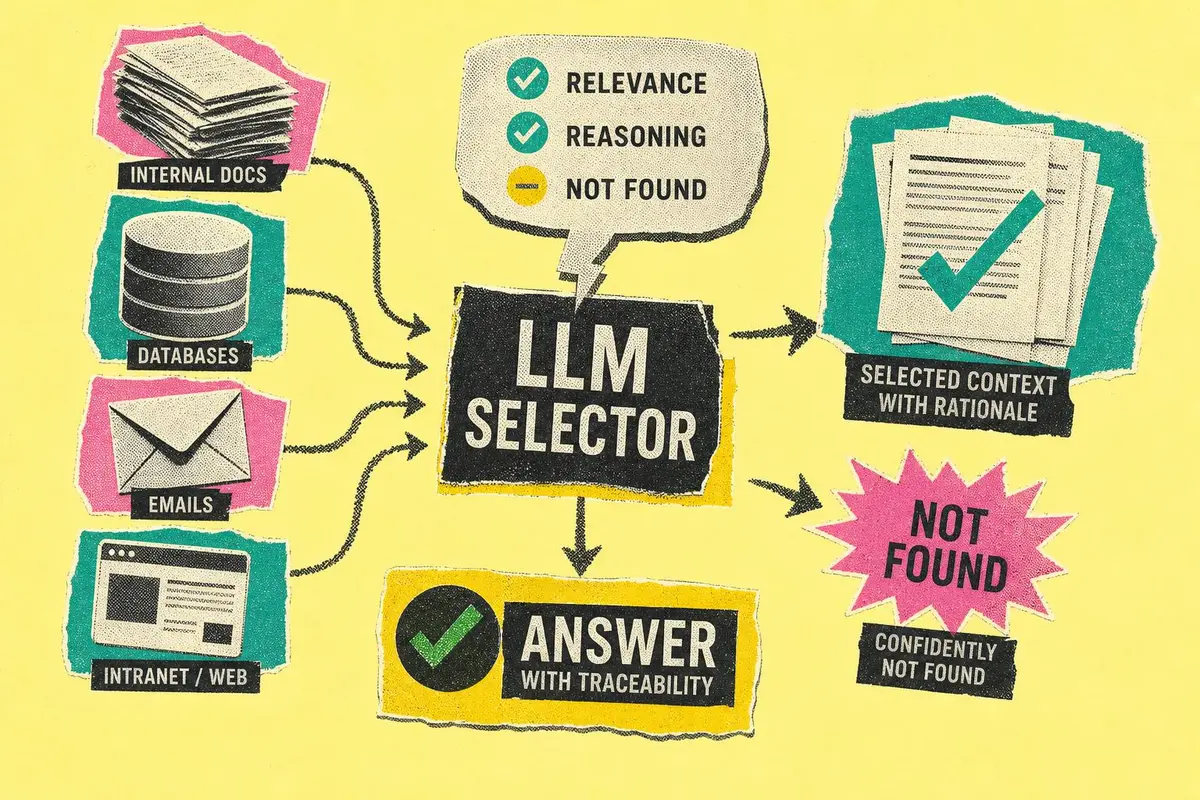
במערכות RAG ארגוניות, הבעיה הגדולה אינה רק יצירת תשובה אלא בחירת המקורות הנכונים לפני כן. גישה מתקדמת מציבה מודל שפה כבורר סופי בין מועמדים, עם נימוקים, עקיבות ויכולת לומר בביטחון שהמידע לא נמצא.
RAG ארגוני חייב בורר, לא רק מנוע חיפוש
אחת הטעויות הנפוצות בבניית מערכות RAG היא להתייחס לשלב האחזור כאל חיפוש סמנטי פשוט: מחלקים מסמך למקטעים, יוצרים Embeddings, שולפים את חמשת המקטעים הקרובים ביותר ומעבירים אותם למודל. זה עובד בדמו, אבל נשבר מהר במסמכים ארגוניים שבהם סעיף, כותרת, מספר תקנה, תאריך או מטבע יכולים לשנות את כל משמעות התשובה.
רוצה להישאר מעודכן ב-AI?
הירשם לדיוור השבועי שלנו וקבל עדכונים, המלצות על כלים, חדשות ודוחות מיוחדים
הכיוון שמוצג במאמר של אנג׳לה שי ב-Towards Data Science חשוב משום שהוא משנה את נקודת המבט: אחזור אינו דירוג מתמטי בלבד, אלא תהליך סינון מבוקר על מבנה המסמך. במקום לתת לנוסחת איחוד ציונים להכריע, המערכת מאפשרת למספר גלאים להציע מועמדים, ואז מפעילה קריאת LLM אחת כבורר שמדרג אותם ומסביר מדוע.
למה איחוד ציונים לא מספיק
במערכות רבות משתמשים בשיטות כמו Reciprocal Rank Fusion כדי לאחד תוצאות מ-BM25, חיפוש מילות מפתח ו-Embeddings. היתרון ברור: אין צורך לכייל ציונים שונים, רק לאחד דירוגים. אבל כאן בדיוק נמצאת הבעיה. דירוג מאבד את הסיבה. הוא לא מספר האם קטע עלה כי כותרת הסעיף התאימה בדיוק, כי הופיעו שתי מילות מפתח באותה שורה, או כי וקטור סמנטי מצא דמיון כללי אך עמום.
במסמך משפטי, פיננסי או רגולטורי, הסיבה חשובה לא פחות מהתוצאה. אם משתמש שואל על סעיף אי תחרות, מועמד מתוך פרק ההגדרות ומועמד מתוך פרק ההתחייבויות אינם שקולים, גם אם לשניהם ציון דומה. בורר מבוסס LLM יכול לקרוא תקציר מובנה של כל מועמד: מזהה קטע, שיטת האחזור שהביאה אותו, כותרת הסעיף, מילות המפתח שהתאימו והקשר קצר מהמסמך. כך הוא מדרג לא רק לפי קרבה, אלא לפי רלוונטיות ראייתית.
היתרון העסקי: נימוק, ביקורת ואחריות
החידוש המעשי אינו בכך שמודל שפה מדרג קטעים. החידוש הוא שהדירוג הופך לאובייקט מובנה עם תפקיד ונימוק: מקור תשובה ראשי, מקור תומך, מקור משיק או מועמד שנדחה. בארגון, זה ההבדל בין מערכת שאפשר להדגים לבין מערכת שאפשר להכניס לייצור.
כאשר קצין ציות, עורך דין או אנליסט כספים שואל מדוע הוצג מקור מסוים, התשובה אינה יכולה להיות דמיון וקטורי 0.78. היא צריכה להיות שרשרת ניתנת לשחזור: איזו שיטה מצאה את הקטע, באיזו כותרת הוא נמצא, אילו מונחים התאימו, מה ראה הבורר, ומה היה הנימוק שלו. זהו בדיוק סוג תיעוד שהופך RAG מקופסה שחורה למערכת מידע ניתנת לביקורת.
Embeddings הם כלי תומך, לא ברירת מחדל
המאמר גם מאתגר את האינסטינקט של התעשייה להתחיל תמיד מ-Embeddings. במסמכים ארגוניים רבים האות החזק ביותר הוא דווקא מילת מפתח מדויקת, קוד סעיף, מספר איור, סכום או מונח מקצועי. Embeddings נוטים לדלל אותות כאלה בתוך ממוצע סמנטי רחב. הם מצוינים כשיש פערי ניסוח, שאלות מושגיות או מסמכים ללא מבנה ברור, אך פחות מתאימים כאשר המשתמש מחפש עוגן מדויק.
הגישה הנכונה היא תזמור דינמי. אם למסמך יש תוכן עניינים נקי, יש להשתמש בו. אם יש מונחים מדויקים, יש להפעיל חיפוש מילות מפתח וקו-אוקורנס. אם השאלה עמומה או משתמשת בשפה שונה משפת המסמך, מוסיפים Embeddings. מעל כל אלה יושב הבורר, שמקבל את התמונה המלאה ומכריע.
היכולת לומר: לא נמצא
נקודה קריטית במיוחד היא טיפול בהיעדר תשובה. Embedding כמעט תמיד יחזיר top-k כלשהו, גם אם הנושא אינו קיים במסמך. לכן הוא מתקשה להוכיח היעדר. לעומת זאת, מילון מונחים מקצועי וחיפוש טקסטואלי יכולים לספק טענה חזקה: חיפשנו את כל המונחים הרלוונטיים, והם לא מופיעים.
בעולם הארגוני, תשובה שלילית אמינה עדיפה על תשובה מומצאת. מערכת RAG בשלה אינה זו שתמיד עונה, אלא זו שיודעת מתי לעצור. השילוב בין אחזור מבני, בורר LLM, חוזה JSON אחיד ועקבות ביקורת הוא צעד חשוב בדרך ממערכות שיחה מרשימות למערכות ידע שאפשר לסמוך עליהן.