נתונים סינתטיים לאימון מודלי שפה: כך NVIDIA משפרת את Nemotron עם שאלות ותשובות מבוססות משימות
NVIDIA מציגה גישה ממוקדת ליצירת נתונים סינתטיים לאימון מודלי שפה גדולים: שימוש במשימות ציבוריות כזרעי יכולת, יצירת שאלות חדשות, הוספת הקשר והנמקה, וסינון קפדני. התוצאות בניסויי Nemotron מצביעות על שיפור במדדי ידע, קוד, היגיון והבנה מדעית.
מעבר מכמות נתונים לאיכות אותות הלמידה
שוק הבינה המלאכותית כבר עבר את השלב שבו השאלה המרכזית הייתה כמה טקסט אפשר להזין למודל. במודלי שפה גדולים, ובמיוחד בשלבי האימון המאוחרים, השאלה החשובה יותר היא איזה סוג של אות למידה מקבל המודל. נתוני רשת כלליים, קוד, מתמטיקה וטקסטים רב לשוניים עדיין חיוניים, אך הם אינם תמיד מלמדים את המודל כיצד לפרק שאלה, לבחור בין חלופות, להסתמך על ידע רלוונטי ולהפיק תשובה בפורמט מדויק.
רוצה להישאר מעודכן ב-AI?
הירשם לדיוור השבועי שלנו וקבל עדכונים, המלצות על כלים, חדשות ודוחות מיוחדים
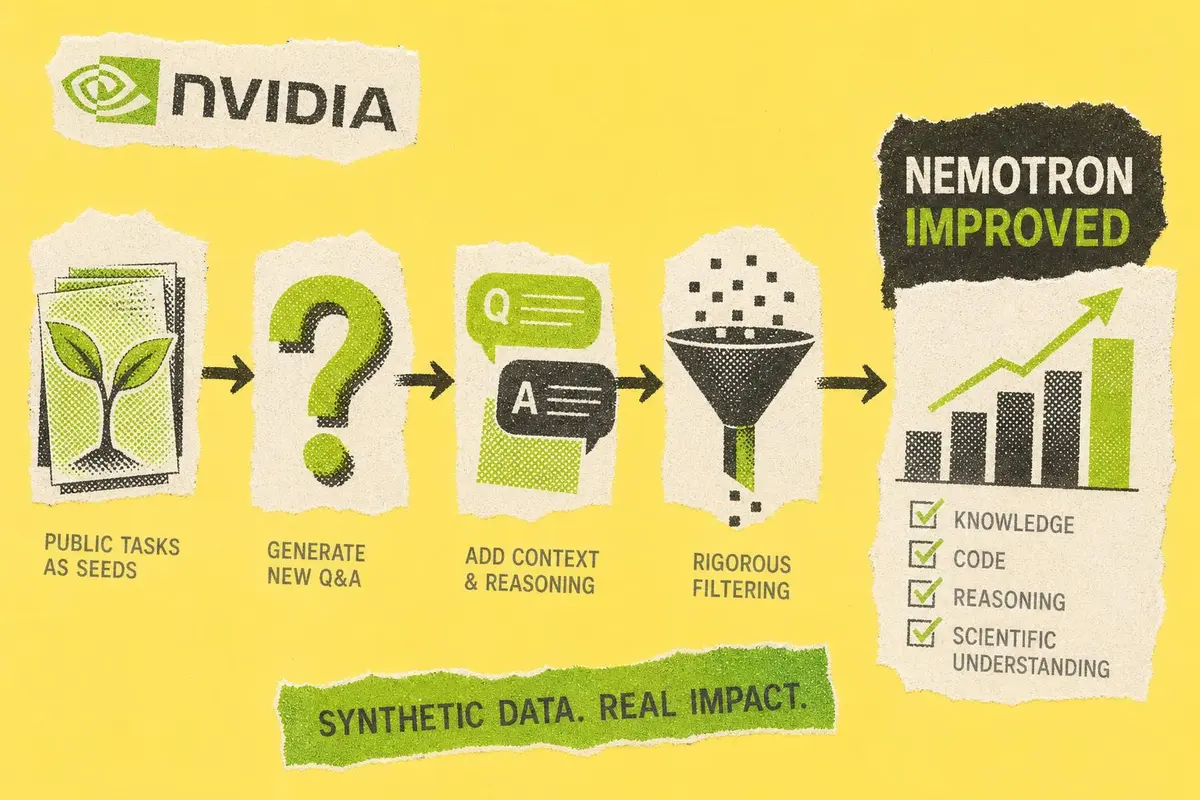
בפוסט שפורסם ב-Hugging Face, דן סו מ-NVIDIA מתאר מתודולוגיה בשם Task-Seeded Synthetic Q&A Generation, כלומר יצירת שאלות ותשובות סינתטיות המבוססות על משימות קיימות. במקום להשתמש במאגרי מבחן כדי לשנן תשובות, השיטה מנצלת פיצולי אימון ציבוריים כזרעים שמייצגים יכולות: הבנת מדע, היגיון, קוד, שאלות רב ברירה, תשובות פתוחות וקריאה בהקשר.
איך עובדת יצירת נתונים סינתטיים מבוססת משימות
התהליך מתחיל באיסוף משימות אימון ציבוריות ממסגרות הערכה רחבות, ובהן כ-70 משימות וכ-700 תתי משימות. כל דוגמה מנורמלת למבנה אחיד, כך ששאלות רב ברירה, שאלות פתוחות ומשימות עם הקשר הופכות לרשומות שקל לעבד. לאחר מכן מודל יוצר שאלה חדשה ששומרת על המיומנות המקורית אך משנה את התוכן, פותר אותה, ומוסיף תשובה סופית לצד הנמקה, ידע רלוונטי או הסבר קצר.
זהו הבדל מהותי לעומת הגדלה נאיבית של דאטה. דוגמה שבה התשובה היא רק האות B מלמדת פחות מדוגמה שבה נכתב בפירוש מהי התשובה ולמה היא נכונה. במודלי שפה, פורמט הפלט הוא חלק מהאימון עצמו. ככל שהרשומה מסבירה טוב יותר את הקשר בין השאלה, הראיות והתשובה, כך היא מספקת למודל מסלול חיקוי מועיל יותר.
למה זה חשוב ל-Nemotron ולשוק ה-AI הארגוני
בניסוי המשך של 100 מיליארד טוקנים על Nemotron-3 Nano, שילוב הנתונים הסינתטיים שיפר את MMLU-Pro ב-1.8 נקודות, את ממוצע הקוד ב-1.9 נקודות, את הבנת הידע השכל הישר ב-1.6 נקודות, ואת GPQA ב-11.1 נקודות, תוך שמירה כמעט יציבה על מתמטיקה. השיפור ב-GPQA מעניין במיוחד משום שמדובר במדד קשה יחסית, המכוון לשאלות מדעיות והיסק מורכב.
מבחינה עסקית, המסר ברור: ארגונים אינם צריכים רק מודלים גדולים יותר, אלא מודלים שאומנו על דוגמאות שמייצגות תהליכי עבודה אמיתיים. בעולם של סוכני AI, מערכות תמיכה, ניתוח מסמכים ופיתוח תוכנה, היכולת להבין משימה, לנמק, להימנע ממסיחים ולהפיק תשובה עקבית חשובה לא פחות מכמות הפרמטרים.
היתרון והסיכון של דאטה ממוקד
הגישה של NVIDIA גם מדגישה סיכון מוכר: נתונים סינתטיים ממוקדים מדי עלולים לשפר מדד אחד ולפגוע ביכולות אחרות. לכן תכנון תמהיל האימון הופך לשכבת מומחיות בפני עצמה. יש לשלוט בדגימה בין משימות גדולות וקטנות, לבדוק כפילויות, לוודא שהנתונים אינם דולפים ממבחנים, ולהפריד בין משימות רב ברירה שקל לאמת לבין משימות פתוחות שדורשות חילוץ תשובה וסינון עדין.
בסופו של דבר, זו אינה רק טכניקה להפקת עוד דאטה. זו תפיסה חדשה יחסית של אימון מודלים: להפוך מערכי משימות ציבוריים למפות יכולת, ולבנות סביבן דוגמאות סינתטיות עשירות שמלמדות את המודל איך לחשוב במסגרת משימה. אם הגישה תמשיך להוכיח את עצמה, היא עשויה להפוך לאחד המרכיבים המרכזיים באימון הדור הבא של מודלי שפה ארגוניים.