מערכות RAG למסמכי PDF: למה שחזור תוכן עניינים הוא תנאי לאחזור מדויק בארגון?
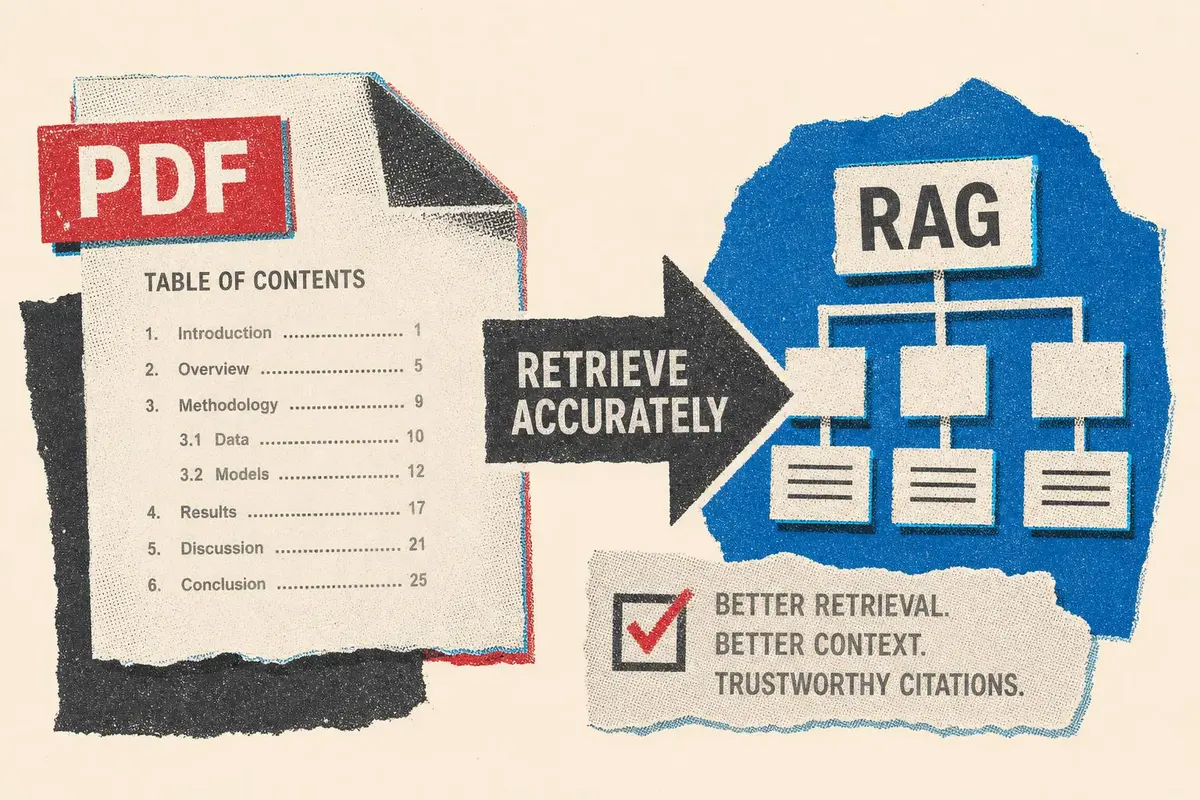
מסמכי PDF רבים מציגים תוכן עניינים לעין האנושית, אך אינם חושפים אותו כמבנה שמכונה יכולה לקרוא. עבור מערכות RAG ארגוניות זו אינה בעיית נוחות, אלא פגיעה ישירה באיכות האחזור, החיתוך והציטוטים.
הבעיה השקטה שמחלישה מערכות RAG ארגוניות
אחת ההנחות המסוכנות בבניית מערכות RAG היא שמסמך PDF הוא פשוט טקסט שמחכה להישלף. בפועל, PDF הוא תוצר עיצובי לא פחות מאשר מקור מידע. הוא יודע להיראות מסודר לקורא אנושי, אך לעיתים קרובות אינו מספק למכונה את המבנה הפנימי הדרוש להבנה אמינה. מאמר טכני שפורסם ב-Towards Data Science על ידי קז'אן שי מתמקד בדיוק בכשל הזה: מסמך שמציג תוכן עניינים מודפס, אך אינו כולל Outline או Bookmarks שהמערכת יכולה לקרוא ישירות.
רוצה להישאר מעודכן ב-AI?
הירשם לדיוור השבועי שלנו וקבל עדכונים, המלצות על כלים, חדשות ודוחות מיוחדים
בתרחיש כזה, פעולת extract_text אינה מספיקה. המערכת יכולה לשלוף מילים, שורות ופסקאות, אך אינה יודעת היכן מתחיל פרק, מהו תת-פרק, ומהו ההקשר המבני שבו מופיעה תשובה. עבור ארגונים שמפעילים RAG על תקנים, חוזים, דוחות רגולטוריים או נהלי עבודה, זו בעיה עסקית אמיתית: תשובה שנראית נכונה אך נלקחה מהפרק הלא נכון עלולה להיות גרועה יותר מאי-תשובה.
תוכן עניינים אינו קישוט, הוא שכבת אינדוקס
מערכות אחזור מודרניות אינן אמורות לחפש רק לפי דמיון סמנטי בין שאלה לפסקה. במערכות איכותיות, האחזור מוגבל לפי אזורים במסמך, החיתוך נעשה לפי גבולות פרקים, והסיכום עוקב אחר מבנה המחבר. לכן טבלת תוכן מובנית, למשל toc_df, הופכת לשכבת אינדוקס קריטית. היא מאפשרת למערכת להבין שהמידע שייך ל"נספח", ל"הגדרות", ל"דרישות אבטחה" או ל"שיטת בדיקה".
האתגר החריף הוא שהמספר שמופיע בתוכן העניינים אינו בהכרח מספר העמוד הפיזי בקובץ. במסמך עם כריכה, הקדמה ותוכן עניינים, פרק שמסומן כעמוד 1 עשוי להתחיל בפועל בעמוד 9 של ה-PDF. אם מתעלמים מהפער הזה, מערכת ה-RAG תנווט בביטחון אל המקום הלא נכון.
שלוש רמות טיפול: מהזול והמדויק אל הגמיש והיקר
הגישה הנכונה היא מפל מדורג. אם למסמך יש Outline מקורי, משתמשים בו. זהו המקרה הטוב ביותר: היררכיה ועמודי יעד מגיעים מהקובץ עצמו. אם אין Outline אך תוכן העניינים מכיל קישורים פנימיים, אפשר לקרוא את אזורי הקישור ולחלץ מהם את כותרות הסעיפים ואת העמודים הפיזיים. זה עדיין פתרון דטרמיניסטי, זול ומבוקר.
המקרה הנפוץ יותר הוא תוכן עניינים מודפס ללא קישורים. כאן יש לקרוא את שורות התוכן באמצעות תבניות כמו נקודות מובילות ומספרים מיושרים לימין, ואז לבצע שלב שרבים מדלגים עליו: התאמת מספרי העמודים המודפסים לעמודים הפיזיים בקובץ. התאמה פשוטה יכולה להישען על היסט קבוע, למשל עמוד פיזי שווה מספר מודפס ועוד שמונה. במסמכים מורכבים יותר נדרש חיפוש טקסטואלי או התאמה מטושטשת של כותרות מול גוף המסמך.
איפה נכון לשלב מודל שפה גדול
הפיתוי הוא לתת למודל שפה גדול לקרוא את כל הקובץ ולבקש ממנו "לבנות תוכן עניינים". זו בדרך כלל בחירה יקרה, איטית ופחות ניתנת לבקרה. שימוש חכם יותר הוא הפוך: אלגוריתם דטרמיניסטי מציע מבנה, והמודל בודק האם הוא עקבי. האם העמודים עולים בסדר הגיוני, האם ההיררכיה סבירה, האם יש דילוגי מספור חשודים. כך ה-LLM משמש שכבת בקרת איכות ולא מנוע ניחוש.
המשמעות העסקית: פחות הזיות, יותר עקיבות
עבור ארגונים, שחזור תוכן עניינים אינו פרט הנדסי שולי. הוא משפיע על אמינות תשובות, על יכולת להציג ציטוטים מדויקים, על בקרת תאימות ועל אמון המשתמשים. ככל שמערכות בינה מלאכותית נכנסות לתהליכי עבודה משפטיים, פיננסיים ותפעוליים, ההבדל בין טקסט שטוח לבין מסמך ממופה הופך להבדל בין דמו מרשים לבין מערכת ייצור שאפשר לסמוך עליה.
הלקח הרחב ברור: תשתית RAG טובה מתחילה הרבה לפני בחירת מודל ההטמעה או ה-Reranker. היא מתחילה בקריאה נכונה של המסמך עצמו, כולל השכבות שהאדם רואה והמכונה מפספסת.